Modern organizations face a paradox in identity governance: access reviews are a critical control for compliance and risk reduction, yet the process is inherently human-bound, time-consuming, and error-prone.
Human analysts and reviewers spend countless hours validating whether each user truly needs each entitlement, often under tight audit timelines and with incomplete visibility across fragmented systems.
At Fabrix, we’re rethinking this challenge through agentic AI – autonomous, reasoning-capable AI-agents that can replicate the cognitive process of an experienced human analyst at scale.
Our UAR Recommendation AI-agent doesn’t just automate decisions; it thinks like a human analyst who has unlimited time, complete visibility, and perfect recall – yet operates safely within the boundaries of enterprise governance.
From Analyst to AI-Agent: Replicating Human Context at Machine Scale
Both human analysts and employee reviewers tasked with user access reviews rely heavily on organizational context. They understand the business structure, know who reports to whom, recognize which applications support which business functions, and can tell which access patterns are normal versus risky.
However, in practice, this process is extremely demanding.
Reviewers are often presented with long lists of users and entitlements, each requiring a judgment call: keep, revoke, or investigate.
Even for experienced human analysts, going through hundreds or thousands of entitlements across multiple systems is a tedious, error-prone, and time-consuming task.
It’s no surprise that many access reviews become mechanical checkbox exercises rather than thoughtful risk evaluations.
The UAR Recommendation AI-agent is designed to take on this cognitive load. It emulates how a skilled human analyst or reviewer would reason; analyzing business structure, application mappings, and user behavior – but does so autonomously and consistently across the entire organization.
It effectively acts as a digital reviewer who understands the full identity landscape and never tires.
Operating Under Real-World Constraints: Partial Data and Context Gaps
Unlike idealized AI systems that assume perfect data, the UAR Recommendation AI-agent is built to operate under imperfect conditions.
In many real-world deployments, entitlement metadata is incomplete, ownership information is outdated, or usage logs are missing. A robust AI-agent must therefore:
- Infer context from partial evidence
- Cross-validate information across multiple sources
- Explicitly track uncertainty in its reasoning
- Defer or lower confidence where data gaps exist
This approach mirrors how a human analyst would work – acknowledging unknowns rather than making blind assumptions.
Key Analytical Dimensions in the AI-Agent’s Reasoning Framework
Each entitlement recommendation is the result of multi-dimensional reasoning. The AI-agent evaluates multiple evidence streams before forming a decision:
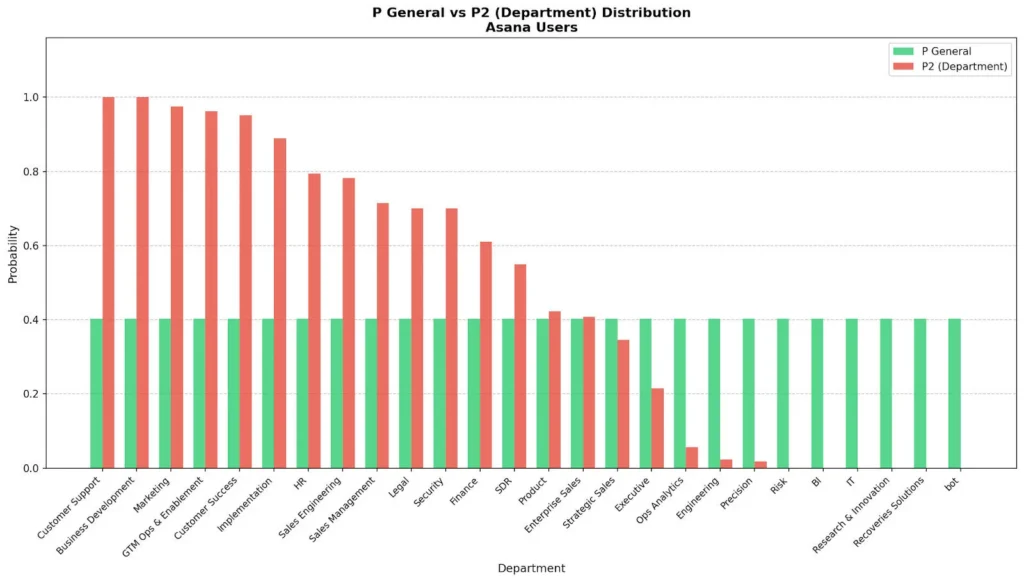
1. Usage-Based Assessment
The AI-agent analyzes actual entitlement usage over configurable time windows (typically 30–120 days).
If a user hasn’t invoked the associated permission, session, or API call in that period, the AI-agent treats it as a potential candidate for revocation while adjusting for entitlement type, role criticality, and application behavior.
2. Peer-Based Comparison
Peer analysis provides contextual grounding. The AI-agent examines similar users (based on department, job title, or functional cluster) and determines whether they hold the same entitlement.
Significant deviations, such as one user having elevated access none of their peers possess, are weighted as anomalies that inform the recommendation.
3. Entitlement-Level Anomaly Detection
At the entitlement layer, the AI-agent detects structural or behavioral anomalies: roles with excessive privileges, toxic combinations, or entitlements assigned outside their intended scope. These anomalies are factored into the recommendation logic as risk amplifiers.
4. Contextual Business Alignment
Finally, the AI-agent maps the entitlement’s purpose to the user’s current role and responsibilities within the organizational context.
For example, an AWS IAM role meant for DevOps automation would likely be unnecessary for a Finance department user, regardless of historic assignment patterns.
From Data to Recommendation: A Multi-Agent Reasoning Loop
Behind the scenes, the UAR Recommendation AI-agent operates as a collaborative network of specialized sub-AI-agents:
- Data Ingestion AI-Agents pull and normalize identity, entitlement, and usage data from multiple systems.
- Reasoning AI-Agents interpret this data, applying rules, heuristics, and learned patterns derived from prior campaigns.
- Assessment AI-Agents synthesize these findings into a confidence-weighted recommendation (Approve, Revoke, or Needs Review).
- Explanation AI-Agents translate reasoning traces into auditor-ready narratives, explaining why a specific recommendation was made.
This agentic architecture ensures transparency, auditability, and continuous improvement as feedback loops refine the AI-agent’s performance over time.
Toward Intelligent Governance
The future of identity governance is not about replacing human judgment but amplifying it.
By embedding human-analyst-level reasoning into autonomous AI-agents, Fabrix enables organizations to scale access reviews across thousands of users and applications while maintaining human-grade context, precision, and accountability.
The UAR Recommendation AI-agent is a first step toward intelligent identity governance, where AI not only automates tasks but truly understands the meaning behind access.